2.6 KiB
dark_net_crawler
暗网采集(新版) ——推送到采集平台的数据字段都和新闻的一样
- 新闻网站:
http://pr3ygifxd23xu43be2fegjjsk5jlb22q2va2h5apz76ejbvammeclkid.onion/
- 交易网站:
http://potshopk4eov76aciyranqyq2r3mszuvfisvneytodfxo56ubha7doqd.onion/?post_type=product
部署说明:
-
线上 47.252.23.168 机器(已翻墙)上,部署了:
(1)项目部署路径:
/opt/crawl/dark_net/dark_net_crawler 沙箱环境: conda activate pdf_crawler_py3.8 python环境为3.8(2)暗网采集代理的Tor服务-------代理地址:socks5h://localhost:9050
CentOS+tor+Privoxy 服务搭建(要出墙tor才可正常使用):
sudo yum install epel-release 不然没有源 sudo yum install tor service tor start 启动服务
service tor status 检查服务状态(3)Privoxy:将SOCKS5代理转换为HTTP代理:http://172.18.1.103:19050(最终暗网采集项目中 使用的代理地址:见 settings.py)
sudo yum install privoxy 安装 修改一下privoxy 配置文件 将tor 和privoxy整合 vim /ect/privoxy/config 将 listen-address 改为0.0.0.0:19095 搜索 forward-socks5t 找到注释拿掉 ESC wq保存退出 启动privoxy service privoxy start 启动完成检查状态 status 这样就完成了服务搭建 设置完成代理 检查是否成功 curl -x http://172.18.1.103:19050 'http://pr3ygifxd23xu43be2fegjjsk5jlb22q2va2h5apz76ejbvammeclkid.onion/' curl -x http://172.18.1.103:19050 'http://httpbin.org/ip' curl -x socks5h://localhost:9050 'http://httpbin.org/ip' curl 'http://httpbin.org/ip'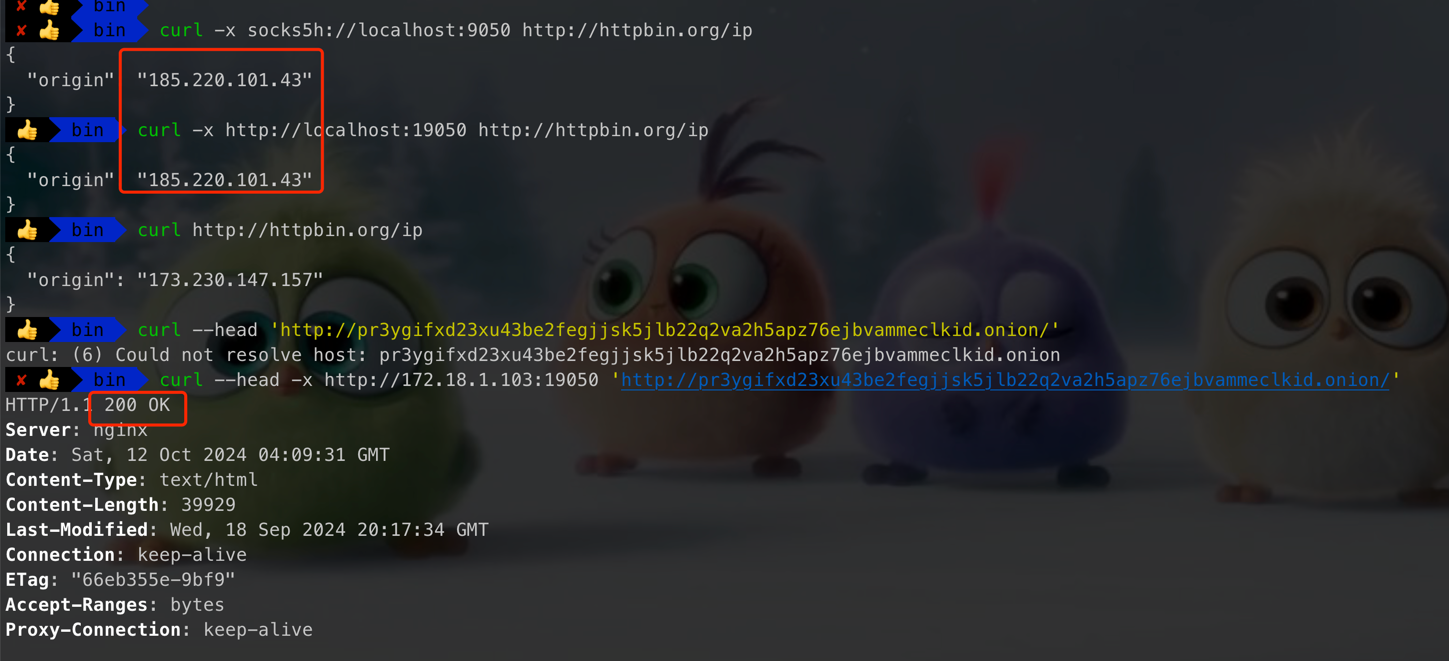
-
本地或线上一次性运行启动入口:python entrypoint.py
依赖安装:pip install -r requirements.txt --python-version 3.8
线上周期定时采集:
conda activate pdf-crawler(进入沙箱环境)
python scheduled_run.py (每周五采集一次)
-
(1) 数据连接的Kafka配置:
dark_net_crawler/utils/kafka_config.py
(2) 输出到采集平台的数据格式:(和新闻字段一致)
见:dark_net_crawler/items.py
如果想把新采集的数据覆盖掉:version字段值递增即可。 items['version'] = 2
-
日志打印--按天输出,只保留近7天:
dark_net_crawler/utils/fb-download-logs/2024-07-18.log
-
两个网站的采集解析逻辑:
dark_net_crawler/spiders/news_denkbares.py
dark_net_crawler/spiders/shop_pot.py